Clusters
1.1 Writing a Request for Proposal (RFP) for a cluster that will succeed
Picture yourself in the early 1980s. You are assigned the task of designing a new computing system. Your guidelines are slim at best. The situation can only be described as: "I don't know what I want, but I will know it when I see it." The only defense against this type of statement is to sit down and write what is called a Request for Proposal.
The Request for Proposal would possibly look like:
I don't know what I want in a computer system, but it should provide at least the following characteristics:
§ Availability
§ Reliability
§ Scalability
The design of the cluster computer system evolved as an answer to such a Request for Proposal.
The term "cluster" as it applies to the computer industry was popularized by Digital Computer Corporation in early 1983 with VMS version 3.7. Two VAX 11/750s maintained cluster communication at the rate of 70 million bits/sec or 8.75 Mbytes/sec. During the past 17 years, many ideas of what the term cluster should mean have been set forth.
When the cluster system was first introduced, the selling point was not the term "cluster." Nobody knew what the term meant. But, people did "know what they would want, if they saw it." Therefore, the selling points were availability, reliability, and scalability, all of which the cluster system would provide. The term "cluster," over the years of development, evolved to become synonymous with these characteristics.
Unfortunately, these same common characteristics of a cluster have become commonplace and are often used interchangeably with the term cluster! Vendors have used the term "high availability" and declared this as their cluster implementation, when, in fact, the system does not provide all the characteristics that a cluster, as originally defined, was meant to provide.
The point is, just because a particular configuration of hardware and software provides a characteristic of a cluster, it is not necessarily a cluster.
This brings up an interesting question: When is a cluster not a cluster? To answer this we need to state firmly what a cluster is, as it was originally defined
1.2 When is a cluster not a cluster?
A computer cluster is a system of two or more independent computer systems and storage subsystems intercommunicating for the purpose of sharing and accessing resources. This is a paraphrase of the VAXcluster definition found in Roy Davis's book VAX Cluster Principles, which states, "A VAX cluster system is a highly integrated but loosely coupled multiprocessor configuration of VAX systems and storage subsystems communicating with one another for the purpose of sharing data and other resources." This definition clearly states what a "cluster" should have. When a cluster is constructed based on this simple definition, the resulting entity will have some very desirable characteristics:
§ Availability
§ Scalability
§ Reliability
§ Manageability
§ Single-system image
Some manufacturers have actually used one or more but not all of these characteristics as testimony of their product's ability to be considered a cluster. For example, "Our system meets the cluster standard of high availability and reliability." This makes about as much sense as saying, "Zebras have stripes; therefore, an animal with stripes is a zebra." Of course, hyenas have stripes as well, and the analogy is just as ridiculous.
A "cluster" is not a cluster when the system described does not adhere to the minimum definition of what a cluster should be. Let's say it one more time, before we move on. "A cluster consists of two or more independent computer systems and storage subsystems intercommunicating for the purpose of sharing and accessing resources."
A system that does meet the definition of a cluster offers the characteristics listed above. Let's define these characteristics and provide some examples.
1.2.1 Availability
Availability is the quality of the system's response to a user or process request. Consider this scenario. You walk into a good restaurant on a Saturday night (without reservation) and ask for a table, and you get "right this way" for a response. Actually, this is an example of highly available. The term "highly available" alludes to an instantaneous response (availability) to a request. The reality of the restaurant scenario, however, especially on a Saturday night, is a wait of at least 15 to 20 minutes.
The reality of a single-server system's availability can be exasperating. Suppose your office has a single server with network applications. You've got a deadline, and you need one more file. It's time for Murphy's law to strike. You've got the connection, the file is selected, and just before you get the transfer, the network hangs. Why? It could be pollen in the air, disk I/O bottlenecks, server capacity limits, or many other things. Nothing short of a complete power outage has an impact on day-to-day operations like this scenario, and, regrettably, it happens far too often in single-server situations. So how do you approach this problem?
There are a number of ways to address availability. The cluster provides a system configuration, which maintains user-perceived availability during subsystem downtime. Some computer system designers use redundancy in their attempts to provide availability. The amount of redundancy used is usually in directly proportion to their level of paranoia.
Common examples of redundancy include redundant servers, redundant networks, and redundant storage subsystems. Redundant servers are, in fact, what some people think of when you utter the word "cluster." Let's defer discussion of this point for now to Chapter 5, "Cluster Systems Architecture."
Redundant networks can be expensive, but they are necessary when network downtime is not tolerable. To be sure, big business and money transactions require stable, available computer systems, but there are computer-controlled industrial process control implementations as well. Consider a steel-producing plant involved in what is termed the "caster" portion of production. These plants turn out batches of 5,000 tons-that's 10,000,000 pounds-of liquid steel per "ladle." The network and computer operation used here is not something that can tolerate a lot of downtime. The statement "Oh, it does that sometimes, just Control-Alt-Delete it" is definitely not used here!
1.2.2 Scalability
The system should be capable of addressing changes in capacity. A cluster is not confined to a single computer system and can address capacity requirements with additional cluster membership. The cluster definition included the phrase "two or more independent computer systems." The cluster system should allow for additional cluster membership to meet the scalability needs of growth, and, ideally, additional cluster membership would not require a reboot of the cluster system.
1.2.3 Reliability
Briefly stated, "reliable" means "sustaining a requested service." Once a proper operation has been initialized by a user or an application, the system should be able to provide a reliable result. Remember the preceding scenario of the poor guy trying to get a simple file from a server. Well, imagine that the system serving the user crashes and really becomes unavailable. Picture this: the transfer is underway and almost complete when-crash! Some applications have recovery capability-that is, the use of temporary files to regain a part of or even all of the transaction. The question is, how reliable is that recovery method?
A cluster could provide a reliable result by providing a "failover" strategy. A system that provides failover provides an alternative path to an initialized request. Interruptions, such as cluster failover for whatever reason (discussed at length later), should be "transparent" to the user or the application. Ideally, should a cluster member or storage system fail during a user-requested action, interruption would be indeterminable as far as the user is concerned. At worst, the interruption to the user's work would be minimal.
Additionally, the cluster system should be resilient to the actions of a user or application. A "renegade" user or application should never cause the downfall of a cluster. The worst that a recalcitrant application or user should be able to bring about would be the "dismissal" of that application or user.
1.2.4 Manageability
A cluster system should be capable of being centrally or singly managed. Ideally, the cluster manager should be able to access and control the "sharing and accessing of resources" from any point in the cluster. This implies two specific but equally important tasks. The cluster manager should be able to modify the system configuration without disturbing the supported users and processes. A manager should be able to shut down and reboot any cluster member or supporting storage subsystem. Further, the cluster manager should be able to control users' access (including the addition or removal of users) to the cluster resources. These two tasks should be capable of being performed on any member system of the cluster or system that has been granted access to the cluster management. Resources, from a user standpoint, should be transparent. Cluster system resources should appear as though they were "local" to the user.
1.2.5 Single-system image
Each computer member of the cluster is capable of independent operation. The cluster software provides a middleware layer that connects the individual systems as one to offer a unified access to system resources. This is what is called the single-system image.
Since each computer member is capable of independent operation, if one member of the cluster should fail, the surviving members will sustain the cluster. Picture, if you would, the cluster as a royal figure of ancient times, when a litter was sometimes used to transport royalty. The litter was supported by six able-bodied men. As the men moved as one, the litter moved as one. If the road got rough or one man slipped, the surviving men would sustain the litter with its cargo. The cluster does not need six independent computers to sustain cluster operation, but two independent systems are required as a minimum to constitute a cluster. This inherent ability of a cluster provides a key ingredient to a cluster's availability and reliability. This independence allows an entire computer to fail without affecting the other cluster members.
The following summarizes the advantages of a cluster with a single-system image:
§ The end-user or process does not know (or care) where the application is run.
§ The end-user or process does not know (or care) where, specifically, a resource is located.
§ Operator errors are reduced.
§ A single-system image typically incorporates both a hardware layer and an operating system service or feature common to each cluster member. The user's or application's point of entry to the cluster is a cluster member's application layer. The single-system image presents the user or application with the appearance of a single-system image-a cluster. The individual supporting members are transparent.
With the advent of its Windows 2000 Advanced Server, Microsoft has introduced its first Windows operating system that addresses the cluster characteristics of availability, scalability, reliability, manageability, and single-system image. Unlike the original VMS cluster or other types of cluster systems of recent years, this operating system does not require proprietary hardware for its implementation.
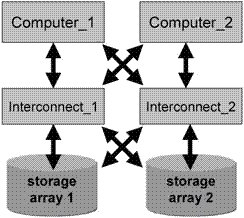
1.3 Subsystems
A cluster system consists of three subsystems (see Figure 1.1):
1. Server subsystem, using two or more independent computers
2. Interconnect subsystem, using two or more computer-storage interconnects.
3. Storage subsystem, using one or more storage systems
Figure 1.1: Cluster system.
It is the combination of these three that provides cluster capability according to our definition, "a computer cluster is a system of two or more independent computer systems and storage subsystems intercommunicating for the purpose of sharing and accessing resources." At first glance, the foregoing definition along with the constituent subsystems might incline a person to declare that a cluster system is merely a means to accomplish fault tolerance.
Fault tolerance means "resistance to failure." Resistance to failure is an obviously desirable trait but is not in itself what clustering is about. Fault tolerance should be considered a component of a cluster's subsystem. In fact, fault tolerance could be a component of any one of a cluster's subsystems or inherent in all three. For example, a component of the server subsystem would be an individual server; a component of the interconnection subsystem could be an individual controller; and a component of the storage subsystem could be an individual disk.
Therefore, the server subsystem contains at least two components-the computers that are members of the cluster.
The interconnect subsystem consists of at least two components: (1) the controllers that provide interconnection between the two computers and the storage subsystem and (2) the "intelligence" or software/hardware combination, which could address a "failover" situation at the interconnect level.
A single RAID "box" could be considered as an entire storage subsystem. (RAID is the acronym for "redundant array of independent disks." An excellent reference on RAID can be obtained through the RAB Council at http://www.raid-advisory.com/.) RAID storage is an implementation of a model or construct of how independent disks work as one. One such RAID model is the "mirror" or exact replication of one disk to another for the purpose of availability.
A cluster consists of three subsystems, and each subsystem consists of components. When fault tolerance was mentioned previously, it was described as an example of a subsystem component. Fault tolerance can indeed be a significant component of all three cluster subsystems. Fault tolerance (Figure 1.2 shows a simple RAID 1 configuration) is and has been an inherent quality of Microsoft's NT Server product line. But Microsoft's NT Server did not have built-in cluster capability, as does the Windows 2000 Advanced Server product.

Figure 1.2: Cluster components.
Another example of implementing fault tolerance as a component of a cluster subsystem is the Marathon computer system. This is a hardware fault-tolerant NT server. But, from our stated definition, a Marathon computer system would be, in itself, a single component of a server subsystem. Several years ago, manufacturers such as Force, Tandem, and Digital Equipment Corporation produced fault-tolerant computers. Digital Equipment's FT3000 VAX had dual "everything" right down to the AC power sources. The system had dual processors, memory, controllers, storage, network cards, and power sources. But even with all that, if you wanted true high availability (with the reliability of an FT3000), Digital had a cluster configuration involving two FT 3000s in a cross-coupled cluster configuration as an available, reliable cluster solution.
RAID boxes, by definition, have fault tolerance. An example of a fault-tolerant interconnect is the dual-ported SCSI adapter as found in the CL 380 Compaq cluster box. Fibre Channel such as the Compaq HA (High Availability series), FDDI, and cluster network interconnects support redundant implementations, thereby adding a fault-tolerant component to the cluster interconnect subsystem. Another example of a cluster component is the clustering software added to the server's operating system. The clustering software must be integrated with the operating system. If a system should fail because of a catastrophic event, the cluster software would be "first-in-line" to take whatever recovery action is necessary.
Components can also be useful in adding to the features of a cluster without being part of a specific subsystem. Such is the example provided with the replication software produced by Octopus and Oracle Replication Server. Replication software can add a fail-safe fault-tolerant component to the cluster server subsystem. Either of these products provides additional features to the cluster system as a whole.
But what about something that would allow enhancement or future revision? This leads to a third level of hierarchy in our cluster system definition-the cluster attribute.
1.4 Cluster attributes
Cluster attributes add features or functions that, while desirable, do not directly contribute to clustering by our definition. An example of this is cluster management software. Since a cluster comprises more than one server, it would be convenient to have the cluster management tools available wherever the cluster manager is located. Today, there are many "cluster-aware" management products and backup software products available that can add desirable features to the cluster system.
Dynamic linked libraries (DLLs) that are written specifically for the cluster middleware software are another example of a cluster attribute. DLLs would provide an extensible foundation for the cluster software to access and enhance the overall cluster operation.
Returning briefly to our overall account of what a cluster system should provide, we see that there are two groups of people with very different needs that must be addressed.
For users, the overall goals of the cluster are to provide availability and reliability.
For managers, the overall goals are to provide scalability, central management, and stability.
This last item, stability, is the strength to stand or provide resistance to change. With regard to the cluster, this comes from the operating system chosen for the cluster members and the ability of the cluster to failover, if need be, to the next available cluster member. The Windows 2000 operating system provides an even more resilient kernel than its NT predecessor in providing immunity to the "blue screen of death" or to an errant process action. And in the event that a subsystem has a failure, the Windows 2000 Advanced Server cluster provides a built-in capability of failover.
This same "stability" characteristic applies to the user as well. The terms we've used from the user's perspective-"available" and "reliable"-imply that when a portion of a subsystem fails, another portion of that subsystem compensates or fails over.
When a failover occurs, there are two categories to consider. These categories are the perspectives represented by the two groups of affected persons-users and administrators. Let's examine recovery from these two perspectives.
1.4.1 User recovery
From a system crash or from an administrative operation session failover, there are two possibilities. The first (and ideal) is that the user has no perceived disconnect. As far as the user is concerned, nothing happened! The second case (and most common) is a lost session-or session disconnect.
The cluster is still available, but the user is forced to reaccess the resource desired. If the application involved is critical and session disconnects are a possibility, then the application needs to involve transactional processing or the capability to rollback to its initial state.
1.4.2 Administrative recovery
From a system crash or from an administrative operation session, failover should include a central control system. The cluster system should have built-in messaging to both connected users and administrators for the purpose of advising impending cluster member removal.
Administrative shutdown of a portion of a subsystem is sometimes necessary for the carrying out of administrative tasks. When a cluster manager performs an administrative shutdown to a cluster member, any resources served by that cluster member are automatically transferred to remaining cluster members.
In summary, we've stated that a computer cluster consists of three principal subsystems-a server, a storage subsystem, and an interconnection subsystem. Together these provide the basis of our original definition of a cluster as a system made up of two or more independent computer systems and storage subsystems intercommunicating for the purpose of sharing and accessing resources. The subsystems are constructed with discrete components, such as the server members and fault tolerance. Cluster attributes are basic system enhancements that enable additional functionality.
Currently, the word "cluster" has become a buzzword. Seventeen years ago the word "cluster" had no marketability, but "availability" and "reliability" did. Today, to gain interest, vendors bend and twist many definitions of what a present-day cluster should be to match their product's characteristics. The term "cluster" has been and is used quite loosely by the press and some vendors to describe high-availability solutions for Windows NT 4.0 Servers and Windows 2000. Some of these "clusters" do not live up to the authors' definition and hence may not provide a constant availability of service.
An "apples to apples" comparison between Windows 2000 Clustering and legacy solutions such as OpenVMS Clusters or NonStop Clustering will probably end up in debates about features and capabilities missing in Windows 2000 Clusters. For all you OpenVMS fans, please see Figure 1.3.
Digital Background Perspective
If you happen to have a background with OpenVMS Clusters, I am sure that halfway through this chapter you might be saying to yourself that "if it ain't got a distributed lock manager (DLM) then it can't be called a cluster." There are two points that we would like to make to you. First, Windows 2000 and Clusters are relatively new. Remember our argument that Windows 2000 is really only at version 3.0. Second, Microsoft appears to have developed architectures today that set a good foundation for future enhancements. Finally, remember the saying that "there is more than one way to skin a cat." With that last comment, don't be surprised to learn that new ways are not always bad.
Figure 1.3: Digital perspective.
As you read this book, you should be focusing on the new challenges that Windows 2000 Cluster products were designed to address. At the same time, remember that Windows 2000 is still a relatively new operating system built to address many new challenges. Therefore, its design goals differ from those of other, traditional operating systems.
1.5 Design goals
Businesses of all sizes are acquiring computer systems at an astonishing rate. It seems that as quickly as they are built, they are being snatched up for use either at home or by business. Just a short time ago, only large corporations or governments could afford a data processing system. Now businesses of all sizes, from mom-and-pop shops to international corporations, are integrating computers into their business processes as fast as they can get their hands on them. The one thing that is more and more common between mom-and-pop shops and large corporations is that the daily successes of their companies are becoming totally dependent on the reliability and capabilities of their data processing systems. This is especially true for companies that are doing business electronically over the Web.
In the global market, the sun never sets! Because of all this, most people who became accustomed to PCs in the 1980s now realize that an occasional "Ctrl-Alt-Del" just won't cut it anymore. PCs are now expected to deliver at the same level of service as minicomputers and mainframes but at a tenth of the cost.
Where there is consumer demand, you will find entrepreneurs ready to provide a solution. So let's take the time to discuss why there is so much money being invested in the cluster industry and why there are so many companies scrambling to position themselves in the emerging Windows 2000 Cluster marketplace.
For example, the merger of Compaq, Tandem, and Digital is an example of three companies that all had independent technology critical for implementing clusters and decided it was time to join forces to leverage off each other's unique capabilities. Tandem's ServerNet and NonStop technology, Digital's OpenVMS Cluster technology, and Compaq's leadership role in industry standard servers has made for a unique corporate marriage.
Microsoft's marketing studies have shown that there is a very large demand for higher availability from application servers than is possible with today's high-volume and low-margin PC class of server. Their customers have taken the plunge from traditional industry-standard solutions such as IBM, DIGITAL, NCR, and HP to the world of PCs with the hope that there will be huge savings, more productivity, and more user friendliness.
What many of these people may not have realized when they made their "leap of faith" decision was that there were some good reasons why these traditional systems were expensive and labeled proprietary. These traditional vendors built their systems from the ground up to provide the reliability that they knew their customers needed (but maybe did not appreciate). Their marketing strategy, if not directly stated, was implicitly one of screaming "you get what you pay for." The customer's pleas of "enough is enough" fell on the ears of Microsoft-a listener. Then the customer settled for less at a greatly reduced price. Herein lies the dichotomy of the past decade. It is between those that settled for the new, the cheap, and the "not so available or reliable" as opposed to those that remember the days of "money is no object" and the legacy systems of yore.
Many of the hardware features specifically designed into legacy systems addressed the issues of reliability and high availability in software applications. These features were included without a second thought, probably for the reason that engineers in those days had a philosophy of "build it the way it ought to be built" because component development demanded extra attention to quality. Disk drive and circuit board development was and is still evolving. So at that point in time, quality-and hence reliability-was viewed by most to be as important as cost. After all, in those days it was easy to spend a quarter of a million dollars or more on a data processing system.
At the other end of the spectrum, too many of us remember the back-ground of the first Windows operating system and the second and the third. We remember hearing, "Oh yeah, it does that once in a while; just do a shut-down and reboot it, and it will go away"! this was addressed to persons experienced in data processing where "shut down and reboot" was not a common procedure. The idea of actually considering a "Windows system" as a replacement for a legacy operating system became interesting only during the past decade.
There is a classic reliability story (circa late 1980s) from the questions put forward by a prospective new information technology (IT) employee interviewing at a large Digital Equipment Corporation customer site. It seems that the prospect asked an employee how long the data processing system would run between crashes. The individual replied that he did not know, after all he had been working at this company for only a year! It has been only recently that the market has demanded this same level of reliability in the high-volume, low-cost market.
This chapter has been citing the former Digital Equipment Corporation as an example, but it is a fact that the firm had a distinct advantage over most of its competitors. Digital had control of the complete systems that they delivered to their customers. The computer was their design, the peripherals were for the most part their design, and OpenVMS was completely under their control. Even the people that serviced the hardware were typically Digital employees. You can do a lot when you can control all the variables, which includes pricing the product for what the market will bear.
Today, that is definitely not the case. Various companies write operating systems. Other independent companies build CPUs, and thousands of companies manufacture and maintain computer peripheral hardware. Because it presents choices and massive competition for any product providing the attributes and features of "cluster systems," Windows 2000 Advanced Server is a "true component" of a cluster system's computer subsystem. And, because there are "choices" to be made, Microsoft realizes that Windows 2000 Advanced Server is just one of many choices available to the market. Hardware manufacturers also realize that there are choices. Proprietary pricing is becoming a thing of the past.
By now, most of us have become used to the Bill Gates way of doing things. We like the user-friendly Windows environment and the plentiful selection of low-cost software development tools and applications-at least until the company's application server hangs and no one can get any work done for a day. But complete trust in the single-server solution represents a pathway to disaster. If a company's computer single-server system goes down, everything stops! Recently we were in a large discount store when the point-of-sale system crashed. Everyone was totally helpless! The employees were standing around without a clue about what to do. Even worse, the store's customers were leaving in disgust (including ourselves). They were victims of an "all your eggs in one basket" computing system. Finally, there is an answer-the cluster-that addresses the single-point-of-failure problem along with many other problems as well.
Businesses today have gone through a dramatic change in the way they conduct business. With the advent of the Web, businesses have the potential to sell to people all over the world. That means the store is open for business 24 hours a day and 365 days a year. With the potential for thousands or even millions of transactions a day, it is easy to see why companies are looking for better than 99 percent availability from their computer systems.
So why, out of the blue, did Microsoft decide to include Advanced Server and DataCenter as a cluster portion of their 2000 product offering? Maybe while everyone was waiting for the PC LAN server to be rebooted, one of the old-timers in information services (IS) said "I can remember the days when we did not have this problem-we had a VAX cluster." The commentator forgets or neglects to state the price the company paid for that cluster and doesn't remember the task force of personnel required to maintain and care for the cluster. Maybe if designers and developers who remember how it used to be began thinking of how it could be, the race would begin for a practical cluster consisting of personal computer member servers.
In reality, there have been cluster attempts and symmetrical multiprocessing attempts since Microsoft's inception of NT 3.1. To be successful in the PC market, it will take a lot more than what was delivered in the past. Today, businesses cannot afford the luxury of large IS organizations with many experienced personnel. Instead, they are more likely to have a few people who have to wear many IS hats. Acting as system manager is only one of the many responsibilities they must assume.
There is a definite need for clustering solutions that virtually install themselves and have very simple and easy-to-use graphical user interfaces. These customer-driven requirements are right in line with the direction cluster vendors have been taking for the Window 2000 Server architecture. In fact, Microsoft is delivering its own cluster software solution for the Windows 2000 operating system, as well as actively promoting open standards for hardware technology that can benefit clustering.
Given the business model in the computer marketplace today, where the hardware might come from one or more vendors and the software also comes from dozens of other vendors, Microsoft and the many hardware and software suppliers must work very closely on developing standards at every level. There are a couple of benefits that we all will see from these efforts on the part of Microsoft.
One benefit that accountants will appreciate is reduced cost. Through the standardization of software application program interfaces (APIs) and hardware architectures, the market is being opened up to many players, big and small. As more players enter the market, competition forces prices down while at the same time pushing technology further ahead. Those of us who are technologists will appreciate the many technical approaches that will be offered to us to make our system hardware faster and more reliable. Since the basic interface specifications can be standardized, the hardware vendors can concentrate on advanced hardware features while being assured that what they develop will work with Microsoft's 2000 operating system.
One such effort, which is discussed in Chapter 7, "Cluster Interconnect Technologies," is virtual interface architecture (VIA). Microsoft is working with more than 40 leading hardware vendors to develop a standard cluster interconnect hardware architecture as well as the software APIs that will drive that hardware.
A complete clustering solution, by our definition, is a very complicated mix of software and hardware. Even with all the work that has been done already by Tandem, Digital (now Compaq), and others, you do not get there overnight. It was very smart on the part of Microsoft to cross-license the patent portfolios of Digital and Tandem. It is still going to take some time for Microsoft to give its 2000 line capabilities similar to those that are already available for VMS and UNIX. Fortunately for all of us, Microsoft has stepped up to the challenge and has laid out a road map for clusters that will get us there over time. The past and current releases of 2000 Cluster Server address just the basic need for availability. According to Microsoft's market studies, that is the most pressing need today for the majority of Microsoft's customer base.
We also need to remember that this is not just Microsoft's responsibility. For us to benefit from Microsoft's clustering "foundation," third-party application developers must rework their applications to take advantage of the high availability and scalability features. These are available to them by taking advantage of new software cluster APIs included in Microsoft's 2000 Cluster Server product. It is only when Microsoft and other applications developers put all their pieces together that we will really see the benefits of 2000 clustering.
Microsoft's stated policy is that the functionality and features that they incorporate into new releases of MS Cluster Service will be a direct result of the feedback they get from their customers. The bottom line is that we cannot get there overnight. Microsoft has certainly taken on a large chunk of work in building MS Cluster Service, but there is an equal amount of work that must be completed by software application vendors and cluster hardware vendors as well. It will happen over time. We recently attended the twentieth anniversary celebration of OpenVMS, and we can attest to the fact that there is still heated debate going on over what new features should be included in OpenVMS Clusters, even after 20 years!
To architect the MS Cluster Service product, Microsoft stepped up to a challenge not attempted before by the IBMs and Digitals of the world. When IBM and Digital sat down to design their cluster architectures, they viewed their market potential in the order of thousands of customers, all of which would be using hardware that the two companies had carefully designed and tested for the specific purpose of running "their" cluster solution. It was a very controlled environment, mainly because there were very few options for customers to choose from.
Microsoft's goal, on the other hand, is to develop its Cluster Service so that it will address the data processing needs of a broad market with the potential for millions of customers. Microsoft has the rather large challenge that these older vendors did not have to address-attempting to deal with all the support issues surrounding hardware manufactured by dozens of system vendors running potentially thousands of different applications. When you think about those numbers, you can then begin to imagine how different their architectural decisions can be.
The potential users of Cluster Service range from small professional offices to large international corporations. A diverse customer base like this needs a solution that is very scalable and easy to support. A small professional office will be just as dependent on its company's databases as a super-large international corporation. The difference is that small companies need a low-cost entry point with the ability to grow the system as their business grows. In addition, they are looking for a system that is very simple to set up and manage.
The large corporations, on the other hand, have the advantage of keeping IS professionals on staff who design, install, and manage their computer systems. It seems, though, that today this advantage is shrinking. Big or small, we are all expected to do more, with less time and help to do it. Microsoft's user-friendly graphical approach to its cluster administration tools will be appreciated by anyone responsible for supporting a cluster of servers.
As we have already said, the first stop along Microsoft's road is simply "availability." This is a straightforward capability for Microsoft to implement. At the same time, it may be just what the doctor ordered for some companies needing to deploy mission-critical applications on Microsoft's 2000 operating system. Even though this initial release falls short by some people's standards for clusters, the bottom line is that you have to start somewhere. By releasing this product (Microsoft project name "Wolfpack") to the market a couple of years ago, Microsoft started the process of encouraging third-party software developers to get up to speed with the new cluster APIs now supported by Windows 2000 Server.
As third-party application vendors come up to speed with the Cluster Server SDK, a whole new breed of cluster-aware applications for the mass market will appear. Further down the road, Microsoft will likely add support for distributed applications and for high-performance cluster interconnects such as storage area networks (SANs). This will not only put them in the same league with the "UNIX boys," but Microsoft will be in a position to set the standards by which all cluster technology will be measured in the future.
The hoped-for, ideal solution would allow a user a Lego style of assembly. Visualize the servers and subsystems as "building blocks" that are nothing more than the standard off-the-shelf computer systems in use today. These "cluster building blocks" can have single-CPU or symmetrical multiprocessing (SMP) CPU configurations. And, they don't have to be configured as identical twins. One machine can have 256 MB of memory, and the other machine can have 64 GB. It does not matter when you cluster. (It will work; but we will talk about some important issues you should be aware of later.) Ideally, you should be able to add and remove these computer building blocks in a manner transparent to the users who are using the cluster.
An alternative to the cluster is the "standby server" system. Those of you who have not had the fortune to work with a standby server type of architecture may be fortunate! Let's just say for now that standby servers can be extremely complex and unforgiving in their configuration. Typically, they are configured with two exactly identical computers (down to the BIOS chip version level), but you can use only one computer at a time. One computer is always in an idle standby state waiting to take over if the primary server fails. Middleware or software, which addresses hardware differences, is available to provide similar results.
A cluster system, which incorporates the single-system image as a cluster component, can share the workload. You can build larger and larger systems by simply rolling in another computer and cabling it up to the cluster.
The following list of points summarizes our discussion on business goals. Keep these in mind as we start to talk about the technical directions and goals Microsoft has taken in the development. The goals of the early cluster initiatives for NT 4.0 have become focused with the advent of the Windows 2000 Advanced Server and Windows 2000 DataCenter as Cluster Server products. Now Microsoft has a product that can:
1. Deliver a high availability solution.
2. Make it very easy to install and administer.
3. Use low-cost industry-standard hardware.
4. Develop based on open standards.
5. Start out small and provide for growth.
6. Develop tools for third parties to extend their functionality.
Chapter 2: Crystallizing Your Needs for a Cluster
2.1 Introduction
The "oxen story" related in the Preface really provides sufficient justification for why a cluster solution should be considered. Why get a bigger server that will eventually need replacing by an even bigger server when what you really need is an additional server? When it comes to lifting a heavy or bulky load, most of us have no problem getting help and sharing the load. Why is that? Two or more people can safety lift a load too big for one. Think about it. You have a big box, cumbersome and heavy, and you need to lift it. Do you go through your list of friends who are Arnold Schwarzenegger look-alikes to find a single person big enough to lift it for you, or do you find two or more friends who can help?
However, when it comes to computer solutions, increased capacity needs are often met with the "bigger server" approach. Before we leave this example, consider this distinction. When two people (or two oxen) move a load, the load is easier to bear. But, if during the process of moving the load, one of the people falls, the entire job stops! Here is where the computer cluster distinction steps up to the plate. A cluster of computers provides the availability to address the load, even at reduced capacity.
Like the oxen story, clusters solutions, in addition to providing many other benefits, have always been able to meet the load-sharing issues. The initial investment for the cluster usually proved prohibitive for all but the absolutely necessary situations. Only recently has the idea of building a cluster become an economical solution for the purpose of load sharing. But clusters provide much more than just load sharing. When computer cluster systems were first becoming popular (15 years ago), the real reasons clusters were the "only" answer at almost any price were their availability, scalability, and reliability.
For the jobs involved in banking, health care, and industry, the costs of providing availability, scalability, and reliability were insignificant compared with the consequences of not doing it. So, at any cost, cluster systems became a solution. And, the term "cluster" became a buzzword.
The Preface of this book provided a simple graph of the transaction per minute benchmark tests conducted by the TPC Organization. The cost of clustering has dropped dramatically in recent years.
Still, with cost always being an important factor, a determination of what is needed on a practical, affordable scale and what is acceptable calls for discussion. Consider the cluster system that manages an international bank's transactions or provides guidance for a manned space flight. These cluster systems require somewhat more stringent specifications than those of numerous other businesses. Clearly there must be a qualitative delineation of systems which are called a "cluster." So, let's divide the classification of cluster into two parts: "cluster" and "cluster plus."
Consider this. Your personal needs require a vehicle to provide dependable (and affordable) transportation to and from work. To satisfy this, the vehicle must meet the minimum requirements and be within a reasonable costs of say $15,000-$20,000. A super Sports Utility Vehicle featuring constant 4-wheel drive capable of "all terrain" and equipped with a mechanical system engineered for a temperature range of -75 to 125° F. with a cost of $75,000 may be a bit more than what you actually need. Clearly, there is a difference between a "vehicle" and a "vehicle plus," just as there is with clusters.
Maybe your business needs do call for the system configuration definedas a cluster. But, perhaps your business needs require things a bit more than just a cluster. Such a system could only be described as a "cluster plus."
Then again, maybe your needs could be satisfied with something less than a cluster, but with cluster attributes. This last suggestion alludes to a system that, although not by definition a cluster, possesses characteristics or cluster attributes. The point is, there is a range of choices available for your needs and you need to crystallize what your needs really are. So, let's talk about your needs.
.2 Acceptable availability
Availability is the time the computer system takes to provide a response to a user or process. Briefly stated, a service is required and is available, given some time. All computer systems are subject to a limitation of availability. Picture yourself in a corporate network environment. You browse the network, find your network application, and double-click. The dreaded hourglass of frustration immediately appears and hovers for what seems an eternity. Is the time you have to wait acceptable? Another example: you come into work and you can't log on to the network, because the network is down. You learn that the network will be available by 9 A.M. Is this acceptable? Acceptable availability is, therefore, a time that all can live with.
To qualify as acceptable availability, the determination is simple. A service is required and is available within a time frame that is acceptable. The restaurant example given in Chapter 1 provides a good illustration of this. You walk into a good restaurant on a Saturday night without a reservation; the maitre d' informs you there will be a wait of 15 to 20 minutes. On a Saturday night, that's acceptable availability. There is a second term you may hear-high availability. Same restaurant, same maitre d', same time period, only this time the maitre d' recognizes you, greets you by name, and offers you immediate seating! That's what is meant by high availability.
Availability is a time-to-action characteristic. But there are also direct and indirect events that can affect system availability. Indirect actions are like system interrupts to a processor. This means the event is outside or external to the control of the system. Direct actions are like program exceptions. This means the event is part of a program or user activity.
Indirect actions or interrupts to normal system operations are almost always unavoidable and also the worst cases. Power failures, network outages, and computer crashes (or, in the case of Microsoft NT 2000, computer "stops") are examples of indirect actions that affect availability. You can imagine such situations. Everything seems to be running fine when all of a sudden-"What happened?" It's gone! No matter how well an application, system, or operation is tested, there will come a time when the rule of inevitability strikes. It is indeed fortunate when hardware failure is the reason for your unavailability. This is fortunate, because hardware can be made redundant and fault tolerant. If you have ever "Web surfed," more than likely you've received a "server unavailable" message at least once. This may be from a server that is really unavailable (crashed) or "maxed out" (no more connections possible). Then there are the application and system failures. And whether it's for a moment of time or seconds of real heart-pounding anxiety, the system was unavailable when needed.
Direct actions or exceptions to normal system operations occur on an as-needed administration basis; these are unavoidable, necessary actions of day-to-day system operation. Hardware upgrades and modifications always cause system unavailability. Operating system patches and upgrades and sometimes even application software installations require system shutdown and unavailability. System backups sometimes require exclusive access to the system. This may reduce server capacity partially or completely and contribute to unavailability.
2.3 Acceptable scalability
Scalability refers to the fact that the system can be modified to meet capacity needs. Acceptable scalability involves four items of consideration of which two could be considered a subset of the second. The items are scalable, downtime, seamless scalability, and non-seamless scalability.
2.3.1 Scalable
First, and most important, to be scalable the systems must have the capability to have their capacity modified. If the system can be modified to an acceptable level without having to be replaced, then the system could be said to possess the first qualification of acceptable scalability. For example, the system motherboard has spare slots for I/O, memory, CPU, and storage.
2.3.2 Downtime
Second, the time required to accomplish the modification is acceptable. Scalability usually requires system operation interruption. Basically the difference between scalability and acceptable scalability is the amount of downtime that is acceptable while the system capacity is being modified. Consider this scenario. You just invested $10,000 for server hardware that is to include redundancy, uninterruptable power supply (UPS), and dual processor capability. The system comes on line and everything is working great. The new database server application will need an additional 100 GB storage capacity! You realize you need to add storage, and the storage system is not hot swappable.
Clearly, acceptable scalability involves careful planning for a system that is scalable without interruption. But this type of scalability, storage space, can be seamless with the right hardware chosen as a system base. This is a classic example of why implementations of hot-swappable disk arrays are sometimes necessary. Microsoft's Windows 2000 operating system takes advantage of this hardware feature by allowing dynamic recognition and importing of additional data disks.
System interruption seems almost inevitable at times. A system that requires an additional central processor or the replacing or upgrading of an existing processor will be necessarily shut down during such a hardware modification. But this is just one classic example of how a cluster system could save the day. If you realize that your system needs some modification requiring a shutdown/power-off situation, a cluster system would allow you to transfer your system operations to the remaining cluster member computer systems. And let's not forget those things that move. Murphy's law dictates that "moving things are more likely to fail than nonmoving ones." Just as car radios frequently outlast the car itself, most modern processors can outlast the cooling fans required to cool them. The problem then is that sometimes the cooling fans are physically mounted to the processor. So how do you replace a burned-out cooling fan on an active processor? Think of it. There are motherboards being sold with $200 CPUs whose survivability depends on the quality of a standard $3.00 "brass bushing" fan.
Symmetrical multiprocessor servers are really interesting in connection with this particular problem. A trouble call is received claiming the server is noticeably slow-it must be the network. A closer investigation of the twin processor server reveals a telltale odor. When the case is opened, the processor fan is observed to be stopped and there's a really interesting blue color on the now expired CPU!
When a processor upgrade from a capacity need is imminent, replacement with good ball-bearing cooling fans should be part of that procedure. Systems with good scalable characteristics should have redundant cooling, alarms, and temperature monitoring in addition to the ability to replace cooling fans during operation. Systems maintenance should require minimal tools and offer ease of access to areas of likely failure, such as fans and disk drives.
The point is that system interruption will always happen to some extent in addressing scaling and capacity needs. How often this happens and the time spent addressing these needs determine the cluster's acceptable scalability. In a nonclustered single-system environment, shutdown for an upgrade to address scalability is almost a given. Consider now the cluster system and what cluster systems have to offer. In a cluster, a new member could be added or an existing member removed, modified, and returned to the cluster to address scalability needs.
Even with clustered systems, however, sometimes a shutdown is necessary. This brings up the last two considerations of acceptable scalability. To ease the time factor of scalability, systems could be considered to possess seamless and non-seamless scalability. "Seamless" refers to a type of operation in which the system at large remains constant and users and processes detect no system interruption for any change to the system.
Seamless scalability requires no shutdown, and absolute seamless scalability is at the high end of the scale. An additional cluster-capable computer system is dynamically added to an existing cluster by configuring the proposed cluster members' parameters. The proposed cluster member shuts down and reboots as it takes on the revised system parameters for cluster membership, but the existing cluster system remains operable during the process. An additional RAID set is added to the cluster's storage subsystem. Because the cluster hardware components were carefully chosen during construction, additional storage elements are a matter of refreshing the system storage utility's display.
Seamless scalability addresses the replacement processor/cooling fan problem. Since the server in need of a capacity change (processor upgrade) can be a removable cluster member, seamless scalability allows continuous cluster operation (albeit at reduced capacity in the absence of the cluster member). Consider this final note about seamless scalability. Seamless scalability includes the ability to repair and restore the system to the desired capacity without total shutdown of the cluster at large. This, of course, does require service personnel to address the hardware changes and software configuration issues. But the cluster remains operable at all times. Therefore, a cluster that can boast of seamless scalability would not be without an operability premium.
Non-seamless scalability is a system capacity modification that would require a complete cluster shutdown. Some modifications always seem to fall into this category (e.g., modifications to the building's power supply). In general, however, single-system environments are non-seamless in meeting their capacity modification needs. Have you ever seen a single-system server have its memory or CPU upgraded while continuing to be powered and serving users?
2.4 Acceptable reliability
Reliability is the ability of the system to obtain a stable state such that the system remains operable for an acceptable period of time. Once a user or a process initiates an operation, the result will be a known state. Even if the power cord is jerked from its socket at what seems to be the most vulnerable moment, the system will produce a known state, not an indeterminate one. Acceptable reliability is a scale or percentage of how well this qualification is met. The perfect score, 100 percent reliability, is unattainable. The famous five 9s or 99.999 percent is what most IS managers would like to see. To obtain this high reliability, the system design must plan for failure and have alternatives for survivability.
Reliability can be thought of as planned as opposed to unplanned.
Planned (or some like to call it engineered) reliability is a system design that provides an alternative to system operation failure. One example can be illustrated by the employment of hot-swappable disks. Hot-swappable storage arrays are a key to continuous reliable service. When a drive element of a storage subsystem array fails, an alarm is set and sometimes an indicator light. The RAID model sustains the integrity of the data stored on the surviving drive. The failed drive is removed and replaced, and the RAID model rebuilds the data to the replacement drive. The simplest RAID form for fault tolerance is RAID 1 or the Mirror set (see Figure 2.1).
Figure 2.1: Mirror or RAID 1 example.
Unplanned reliability-crash! Planned reliability is a system design that provides alternatives to system failure. Unplanned reliability is what happens when you run out of alternatives! System failure is the nice term to describe what has traditionally been known as a crash. The advent of Microsoft's Windows NT introduced an even gentler term to describe this action. As mentioned before, Microsoft refers to a system failure as a stop. However, this term is seldom used in deference to the more popular term blue screen of death (BSOD), so named for what appears on the screen when it occurs.
With a cluster, however, when this unplanned event occurs, reliability could rest with the surviving cluster members or nodes. Acceptable reliability should address two important issues: process and data. Let's start with data.
Data integrity is key to acceptable reliability. Care must be taken to ensure that the data is not corrupt or in a questionable state during and following a system crash. The cure for this is threefold.
1. Replicate your storage. Each time a write of data is issued to the primary storage unit, a copy of that data is written to a second storage unit. This operation is described by RAID model 1 (redundant array of independent disks).
For faster storage, but with data integrity, use RAID model 5 or striping with parity (see Figure 2.2). Here a file that would normally take four I/O transfers is stored, with integrity, in just two transfers.
Figure 2.2: Stripe with parity or RAID 5 example.
2. Back up your data. Do this on a basis directly proportional to your level of paranoia. Can your operation survive, should it need to, on two-day-old data? If not, you need to back up your data every day. Most operations require a daily backup of operational data. Fortunately, Windows 2000 comes with a built-in robust backup utility that even allows scheduled disk-to-disk network backups.
3. Transactional processing. Data operations, which are critical, should always employ a transactional processing file system as part of data management. The Microsoft NTFS file system has employed transactional processing from its introduction in NT 3.1. But, what is transactional processing? Transactional processing is a client/server operation involving two simple phases of operation-prepare and commit.
To illustrate this process, consider a transaction with an ATM machine (money machine). This is a transactional process involving a client (the ATM) and the server (the bank). A user proposes a transaction at card insertion. During the session, one of two things will happen. The user will walk away, happy, money in hand, and his account will be debited for the amount of transaction. Or, the user will walk away, sad, no money, but his account will note debited for the transaction amount. The point is that at any phase of the transaction, even if lightning should strike the ATM machine (granted the user may be surprised), the transaction can be "rolled back" to initial conditions, thus preserving data integrity.
Now, comes the consideration of acceptable reliability relative to the process. The process, the user or application, resides on a computer system. If there is only one computer system and that computer system fails, the process or application fails. The computer system itself becomes a single point of failure. But what if two or more computer systems could interact with the same storage array as with a dual-port SCSI controller or Fibre Channel. This would be a cluster. This follows the definition "two or more independent computer systems and storage subsystems intercommunicating for the purpose of sharing and accessing resources."
If this is the case, then one cluster member computer system could fail and the remaining systems could take charge of the user or application process. But even though the remaining computer systems are members of the cluster, the member is still a different computer system. Then what starts the user or application on the surviving member of the cluster?
Process restart can be manual. This means that an operator must be present to complete the change of operation from the "failed" portion of the cluster to a surviving cluster member. This, then, would be a new instance of the process. Consider a user involved in a terminal access process such as OpenVMS or a UNIX session or a Microsoft Terminal Server client. If a user were connected as a terminal access process at the time of the crash, the user would lose connectivity. The worst thing that user is faced with in this situation is a "hung" terminal window. The user will have to know how to "kill" or terminate the lost session with the server. The user would then have to start a new terminal access to the surviving cluster member. The danger inherent in this type of system is reflected by the inevitable question, "What happens to the data at the time of the crash?" This is where the operating system and the associated file systems used must offer the previously discussed "ATM-like" transaction processing used by Windows 2000 NTFS.
Process restart can be automatic. For critical applications, a restart or resume of the application on the surviving member should be automatic. If the failover involves a "start" of an application on a surviving node, there will be an obvious start delay. What if a "start" delay is unacceptable and failover must be so fast as to be transparent to cluster operation? (Transparent to the operation means that an operator is unaware that a failover has taken place-except for an alarm event.) Clearly this subdivides "restart" into two categories, which can be referred to as active/passive and active/active.
Active/passive (see Figure 2.3) refers to a configuration requiring the application to be "started" and bound to the required data. When system failure occurs, for example, Server_1 crashes, and the surviving member, Server_2, must take control of the database and start the application. This takes time. How much time will be the determining factor in whether the active/passive method offers a solution of acceptable reliability.
Figure 2.3: Active/passive.
Active/active (see Figure 2.4) refers to a configuration allowing two instances of the cluster application. But only one instance of the application has data access. As shown, the application need only enable the data selection to "resume" activity.
Figure 2.4: Active/active.
Microsoft refers to applications that can utilize the cluster application program interfaces and cluster libraries as cluster aware applications. However, Microsoft is quick to point out that applications that are not cluster aware may be restarted via automated script files. Applications that are cluster aware make up a growing list. Microsoft's BackOffice products, such as SQL and Exchange, and Microsoft's Windows 2000 Server services, such as DHCP, WINS, and DNS, are some of the more notable cluster aware products.
Please note that the active/active, like the active/passive has a path from either computer system to the storage array. Also note that only one system at a time has actual access to the storage array. This arrangement is sometimes called a "shared nothing" storage array because the drive is never "shared" between the computer systems. At any time instance, the drive is "owned" by a single computer member.
Shared disk (see Figure 2.5) clustering was developed by Digital Equipment Corporation's OpenVMS clusters. Any cluster member's process or application could access any disk block for which it had permission. The trick is not to allow one system to modify (write) disk data while another system is accessing (reading) data. Synchronized access of the common storage area was the function of an application distributed and running on all cluster members known as the distributed lock manager. This application used a database common to all cluster members known as the lock management database. Each file or data store for the common disk had an associated data structure called the "lock." The lock stored ownership and access privileges to the file or data store. In order for a process or application to read or write to the database, a lock or data structure of assigned access had to be obtained from the distributed lock manager and stored in the lock manager database.
Figure 2.5: Shared disk.
The distributed lock manager service identified three specific things-the resource, the cluster node with current responsibility, and the resource access permissions. This last, third element of permissions is that to which the term "lock" referred. The permissions for each cluster resource were granted or locked in accordance with the lock manager. The advantage of the shared-disk cluster system is that it provides a common base for programs. In a read-intensive environment, the shared disk system offers faster service than shared-nothing. An environment that is subject to frequent writes requires the distributed lock manager to constantly synchronize the access. Despite this required cluster traffic between cluster members, there is a huge advantage to this distributed lock manager middleware. Little has to be done to ensure that the applications are cluster aware.
Database applications are easier to develop in a shared-disk environment, because the distributed lock manager takes care of the disk synchronization. However, most databases use row-level locking which leads to a high level of lock management traffic. Shared disk systems can generate 100 times more small lock level messages than non-shared disk systems. In short, shared-nothing designs are more efficient, but require more program development.
The ability of a cluster to produce acceptable reliability by restarting a process manually or automatically on a remaining cluster member can be termed "failover." The degree of failover capability is dependent on the cluster's reliability needs. Each of a cluster's subsystems can possess failover capability. Let's look at examples of each.
2.4.1 Server failover shared disk
When an individual cluster member fails, for whatever reason, the last messages communicated from the server amount to a "node (or server) exit" announcement that is translated by the remaining nodes as a "remove node from cluster" message. Even if the message is not received from the failing cluster member, the cluster should be able to detect the member loss and "failover" that member's responsibilities. How would this be possible? Let's look at an example of this in the shared-disk design used by the VMS cluster system.
The lock manager database and the lock manager service play a key role. Because each member of the cluster had and ran a copy of the lock manager service (hence the term distributed lock manager) and had access to the lock manager database, access to the unified database of all cluster resources would be held by all cluster members. An exact accounting of which node, which resource, and what access would be listed. In the event of a node failure, the resources and accesses of the failed node would be redistributed to the remaining cluster members. A distributed lock manager and associated database as briefly described here represent a cornerstone for proper cluster operation. For more information on this, please see (Roy Davis, 1993). [1]
2.4.2 Server failover non-shared disk
Microsoft uses a database called the "resource group" in Windows 2000 Advance Server and DataCenter. This structure marks a great forward step in tracking cluster resources by node. This database also provides entries for resource:
§ Dependencies. What conditions must exist for this resource to exist? These are set like a "rule" or test of initial environmental conditions for a given resource.
§ Registry entries. These are specific additional registry entries (or system parameters) that an application or the system can reference.
§ Node. This is an access table, which permits the cluster manager to specify which node(s) a resource is allowed to use.
2.4.3 Storage failover
From its first release of Windows NT 3.1, Microsoft offered a software solution to failed data. Microsoft's solution was a software implementation of the RAID Advisory Board's level 1 model. A "mirror" or RAID 1 drive set provides an exact copy, block by block, of a given partition between two physically different disks, regardless of controller, manufacturer, or geometry. For the truly paranoid, Microsoft's disk duplexing added different controllers for the mirrored pair in the event of controller failure. Hardware solutions abound for all levels of RAID, especially RAID 1 (mirroring) and RAID 5 (striping with parity). When the term "RAID" is used by itself, most likely the level of RAID referred to is RAID level 5 (striping with parity).
Table 2.1 provides a brief description of the common RAID levels.
Table 2.1: RAID Technologies
RAID Level
Common Name
Description
Disks Required
Data Availability
0
Striping
Data distributed across the disks in the array. No data check
N
Lower than single disk
1
Mirroring
All data replicated on N separate disks (N usually 2)
N, 1.5N, etc.
Higher than RAID 2, 3, 4 or 5; lower than 6
2
Data protected by Hamming code check data distributed across m disks, where m is determined by the number of data disks in array
N + m
Much higher than single disk; higher than RAID 3, 4, or 5
3
Parallel transfer with parity
Each virtual disk block sub-divided and distributed across all data disks; parity check data stored on a separate parity disk
N + 1
Much higher than single disk; comparable to RAID 2, 4, or 5
4
Data blocks distributed as with disk striping; parity check data stored on one disk
N + 1
Much higher than single disk; comparable to RAID 2, 3, or 5
5
"RAID"
Data blocks distributed as with disk striping; check data is distributed on multiple disks
N + 1
Much higher than single disk; comparable to RAID 2, 3, or 4
6
RAID 6
As RAID level 5, but with additional independently computed check data
N + 2
Highest of all listed alternatives
Note
N = 2
Source: Paul Massiglia, The RAIDbook, St. Peter, MN: RAID Advisory Board (1997). [2]
Note that the above models described in Table 2.1 may be combined to form the desired characteristics. For example RAID 10 uses striping without parity and mirroring. The technique can be referred to as "mirroring the stripe sets."
However, storage failover is not limited to a failover within "a" RAID model. Storage failover can encompass failover between storage arrays. The storage arrays themselves don't even have to be local! Storage area networks provide an additional safeguard and data availability. This deserves more detailed discussion (see Chapter 7, "Cluster Interconnect Technologies"); the focus of this chapter is to "crystallize" or determine what your needs may require.
2.4.4 Interconnect failover
Finally, this refers to the connection from server to storage as well as the connection from server to server. The server failover described was dependent on the surviving member's ability to detect a server exit. A simple single-server system with a single- or dual-controller local to the server can detect a disk failure.
At the low-end implementation of Microsoft Windows 2000 Advanced Server Cluster, the cluster system typically uses a "private" 100 Mbps internal network for cluster system communication and a SCSI controller to address the storage subsystem. But to detect a server failure you really need an interconnection mechanism that can address interprocessor communications as well as interface the storage subsystem.
The two most popular communications mechanisms use Fibre Channel and/or Small Computer Systems Interface (SCSI) for interprocessor or system-to-system communication. Legacy interconnect systems originating from Digital Equipment Corporation included CI-Computer Interconnect (70 Mbps); DSSI-Digital Standard Storage Interconnect (30 Mbps); and FDDI-Fibre Distributed Data Interconnect (100 Mbps). Network interconnection between cluster servers is proving to be a most interesting technology. For a long time, network interconnects wallowed in the slowness of a 10 Mbps limitation, competing with the typical local area network congestion. Now, technology is on the threshold of commonplace server-to-server communication beyond 1 Gbps. Interconnect failover capability is a simple matter of configuring redundant networks. Couple this with net work storage arrays-or network array storage (NAS)-and you get a setup that is illustrated in Figure 2.6.
Figure 2.6: Cluster storage array.
2.5 Cluster attributes
Cluster attributes add features or functions that, while desirable, do not directly contribute to clustering according to our definition. But when you are deciding on what your cluster needs are (and writing the cost justification), listing those hardware and software needs up front may be to your advantage. An example list follows:
§ Cluster management software. Perhaps the management software accompanying your choice is not adequate to your needs, and a layered product is deemed appropriate.
§ Backup software. If it's not part of your cluster system's choice or adequate to your needs, backup software may be necessary.
§ Load balancing. Most storage array providers have the capability of static load balancing the I/O requests among the redundant storage arrays. There is an exception. One old adage states "it costs that much, 'cause it's worth it." Some storage controllers can be paired to provide the capability of dynamically adjusting the I/O load between controller pairs.
§ Libraries. Does the cluster system of your choice provide attributes that your software can interface?
3.1 Introduction
The preceding chapter on "cluster needs" introduced the capabilities and possibilities of cluster systems. And, certainly the terms availability, scalability, and reliability seem a little easier to understand. But what about the "how"-the way these capabilities come about from within the cluster subsystems? Consider how the components of a clustered system work together as you would the elements of a football game.
In football, the principal goal is for a team of persons to carry a football from one end of a field to another, repeatedly, while fending off opponents who try to prevent this from happening. At any one time, only one person has the ball. That person's fellow team players will position themselves and work to present the best possible avenue for the ball carrier to succeed. Some players will work to provide a reliable block to the opposition, while others will avail themselves to the ball carrier in case the ball carrier is attacked or becomes unavailable. Each team member has a specialized job to help ensure that the goal is met. Woe to the team with the "individual" player. Anyone who has seen or played in team sports has seen the player who is absolutely convinced that only one can meet the goal-himself. The goal on the football field is always attained by the team whose members act as one and yoke their common strengths and abilities. Certain members of the team have "backup." For example, there are two guards, two tackles, two ends, and two halfbacks. In any given "play" of the game, the team and member job division provides availability, in case one member fails, and hopefully, a reliable play conclusion.
The analogy is simple; a cluster system consists of a number of "members," sometimes "pairs" of members. The members have unique, specialized jobs designed to achieve the goal-continuous and robust computer system operation.
The control and operation of the cluster mechanisms are governed by parameters inherent to the cluster mechanisms. A Microsoft Windows 2000 system, which supports clustering, needs to store the parameters in the Microsoft Windows 2000 database, called the registry. The registry is divided into two principal areas-an area for users (HKEY_USERS) and an area for the operating system.
The operating system part of Microsoft's Windows 2000 registry is referred to as HKEY_LOCAL_MACHINE. Successful cluster operation depends on specialized cluster software working independently and with the operating system. Therefore, the parameters of cluster operation would be part of two registry subkeys (see Figure 3.1):
1. HKEY_LOCAL_MACHINE\Software, for the general (e.g., software name) and initial parameters.
2. HKEY_LOCAL_MACHINE\CurrentControlSet\Services, for the cluster-specific operational applications employed as services. The applications (programs) relative to the cluster operation must operate independent of user control. Therefore, those applications specific to cluster operation are deployed as Microsoft Windows 2000 services. Services can operate independently of user control and at a level closer to the system hardware than a user-controlled application.
Figure 3.1: Microsoft Windows 2000 registry.
Clustering software is a "layered" product. This means that the cluster software is in addition to the base operating system's operation and may be manufactured and sold separately from the manufacturer of the operating system. Since the software is an addition, the actual names of the terms may vary from vendor to vendor, but the use and employment will be the same. For example, one of the terms examined will be the cluster member. Some vendors refer to the cluster member as a node. This chapter intends to introduce general terms associated with some of the methods or mechanisms of clustering.
3.2 Cluster membership
Members of a cluster are referred to by some cluster software systems as nodes. The number of computers, which can be nodes or members of a single cluster, is determined by the capabilities of the cluster software. The cluster software inherent to Microsoft's Windows 2000 Advanced Server limits the number to two. Other vendors provide for many computers working as one cluster system. A cluster system includes a specific set of rules for membership. Some clustered systems use Voting as a basic rule for membership.
Voting. A computer typically becomes a member of a cluster by presenting the cluster manager with its computer name and a vote. The vote is a system parameter (typically named vote) with a numerical value of one or greater. Notice that the vote is a numerical value. By allowing the vote to be a variable, the vote could be used to bias the election for cluster membership. The cluster manager authenticates the computer name against the cluster membership database. The vote value is used to determine cluster operation.
Baseball (backyard or street baseball) was always a difficult game to get going in the summer. Most of the regular players were at camp, vacation, or otherwise unavailable. So, the pickings got slim for what was an acceptable number for a game. Somehow the "pickings" for cluster membership have to be set into a rule.
Cluster systems are conducted like an orderly business meeting. A cluster system is not operational as a cluster until a numerical parameter called quorum is met. As is the baseball example, quorum is the minimum number of "players" needed to play.
Quorum is a cluster management parameter whose value determines the cluster system's operability. Typically this operability is derived from the following algorithm:
This algorithm derives the already stated "two or more systems" as a minimum for cluster operation. If each cluster member casts one vote, then quorum would be 2. Note that quorum is an even integer, and the results of the algorithm are rounded down to the next whole number. If a cluster consisted of three members and each member had one vote, the algorithm would produce 2.5 which would round to 2. For a three-member cluster the quorum value should be 2.
There are two cluster configurations that deserve more discussion. The cluster is based on the combination of independent computer systems. This means that some cluster members may be more "desirable" as cluster members than others. Then, there is the situation when a minimal cluster, of only two members, temporarily loses one of the members. Does the cluster system, along with the cluster software, go down?
What about that period of time during which one node is "down"? You may need to shut down a cluster member in order to change the hardware configuration. Or, how do you have a cluster while the other system is booting? This is where the quorum disk comes in.
A disk configuration can have a proxy vote. When a cluster system contains a storage system common to two or more computer systems, the cluster manager can vote on behalf of that storage subsystem. Each computer system of this configuration must be capable of accessing this common storage system. Consider a cluster system with a quorum disk. As the first computer system member boots, that system attempts to access the common storage system. During the access, the cluster manager acknowledges the successful access of that storage system by casting a vote in behalf of that storage system (or proxy vote) to the quorum algorithm. With respect to the Microsoft Windows 2000 system, the successful access is usually directed to a specific partition. The partition needs no restrictions other than a common drive letter for accessing computer systems. That is, the partition used for quorum could be a single, mirror, or striped partition. Take a look at Figure 3.2.
Figure 3.2: Quorum disk.
Figure 3.2 shows that even while a single server is booting, one server and a quorum disk can meet a quorum of 2. This is fine. Even with a two node system, the cluster software and operation remain intact with only one cluster member. However, the availability and reliability factors will be "out the window" during this time when only one cluster member is operable.
This is similar to the cluster system achieved by Microsoft's Windows 2000 Advanced Server in two-node cluster configuration. When the Microsoft Advanced Server 2000 cluster boots, the cluster manager service does not acknowledge the cluster until notification from at least one cluster member as well as the proxy for the quorum disk are received. The proxy vote is generated from the cluster manager upon successful access to the "S:" partition.
When a cluster has three or more members, there is no need for a quorum disk. Quorum can be established by any two of the three computer system members. But what about computer systems of different capacities? Is there some way to favor one computer system member over another?
The beauty of a cluster using the algorithm shown previously lies in its ability to address cluster members of different capacity. Consider a cluster whose members vary in capacity such as symmetric multiple processor servers or large memory servers as shown in Figure 3.3.
Figure 3.3: Quorum example.
In the example shown in Figure 3.3, Server_1 and either Server_2 or Server_3, being online, could achieve cluster operation. In the absence of the "big" node, both of the smaller systems would have to be on line for cluster operation. Note, that the quorum disk had a "0" vote. In general, there is no real need for a quorum drive in a three-node cluster.
Check out the details of the symmetrical multiple processors (SMP), computer systems used for http://www.tpc.org/ tests. The systems used in the tests for the Transaction Processing Council are the biggest and best systems their respective members can build. Those systems may exceed your computing needs. But, what if a large server was available for your cluster operation. The larger capacity servers could be "favored" by increasing the numerical value of the vote parameter.
However, in the above example (and because of the large disparity between the computer system capabilities), a different problem could arise. If the "big" server (SMP system with the 16 GB of memory) is offline and inaccessible for a long period of time, the system falls back to a basic two-node cluster configuration. In order to have cluster operation, both of the smaller servers would have to be online to satisfy the quorum algorithm. Cluster operation could "hang" until both members were available. Therefore, there is a problem if the "big" server were to be offline for an extended period of time.
The cluster software should be configurable to allow the dynamic changes to the parameters for quorum, vote, and quorum disk. The cluster should not require any member to reboot in response to changes to the quorum algorithm parameters.
3.3 States and transition
A cluster member (of any vendor's cluster product) has, at least, four discernible states or conditions during membership. These states represent the condition or status of the cluster members to the cluster manager.
§ Joining-entering the cluster. This state is sometimes called booting, but the meaning is the same. The cluster membership is increasing and the cluster manager could redistribute the cluster load.
§ Exiting-leaving the cluster. This state must be attainable automatically in the event of a cluster member failure. The cluster membership is decreasing, and the cluster management software must recalculate the quorum algorithm to ensure quorum (the number of computers required to operate as a cluster). The cluster manager must redistribute the exiting cluster member's load to the remaining cluster members.
§ Running-operable for cluster tasks. A cluster member must be running or ready to receive a cluster task assignment. A cluster member must be in the running state in order to carry out the cluster task.
§ Transition-cluster member assignment or reassignment of task. Cluster tasks are assigned and reassigned sequentially to a cluster member. During this time, the cluster member is usually unable to perform other cluster duties, and is therefore unavailable.
Think of the last two states, running and transition, as the "running backs" of a football team. The player (cluster member) has to be "open" (running or ready) to receive the ball (the cluster task). During the time the ball is in the air and throughout the events up to the "catch" and the "hold on to the ball," the play is in transition.
3.4 Cluster tasks or resources
A cluster task (sometimes referred to as a resource) is an activity traditionally bound and inherent to single-computer operation. The cluster operation allows these tasks to be distributed and therefore shared by the cluster members. The terms used in the following text may vary from vendor to vendor in their name, but their functionality is the same.
3.4.1 Cluster alias
This is the name shared by the cluster members. As in football, each team member has an individual name (computer name). But once the player becomes a member of the team (cluster), the player plays as a part of the team name (cluster alias). When a computer operates as an individual server, network shares are accessed via:
§ \\computer-name\share-name
When a computer is a cluster member, network shares may be accessed via:
§ \\cluster-alias\share-name
3.4.2 Cluster address
This is the 32-bit Internet Protocol address shared by the cluster members. What a convenience! Like a shopping center offering one-stop shopping, the cluster address allows users to worry only about a single address for things like SQL, Exchange, and Office Applications. One may argue that an enterprise can already do this by just using one big server. But, then what happens if that one big server goes down?
3.4.3 Disk resource
This is the name or label given to a disk or disk partition (part of a disk) that can be assigned by the cluster manager to a cluster member (see Figure 3.4).
Figure 3.4: Disk resource.
3.4.4 Cluster service or application
This is the name or label given to an application or service. The cluster manager uses this name to assign this task to a cluster member. It may seem redundant to give a name to an application, which already has a name, but there is a reason for this. By providing a name, associated parameters can be assigned. These parameters could include:
§ Names of cluster members capable of running or permitted to run this application
§ Groups or individual users allowed access to the application
§ Times or schedule of application availability
3.4.5 Other resources
Additional miscellaneous resources may include:
§ Cluster event messages, which are for error logging and traceability
§ Cluster scripts, which are for structuring cluster joining, exiting, and transitions. Typically these take the form of a command procedure and may use PERL as a construct.
§ Configurable cluster delays, which may be useful to allow "settling" before a "next" action
3.5 Lockstep mirroring
Lockstep servers are composed of redundant components. Each area that could fail is replicated via dual processors, memory, I/O controllers, networks, disks, power supplies, and even cooling fans (see Figure 3.5).
Figure 3.5: Lockstep setup.
Each area includes a cross-coupled means of communicating with its redundant area. Each instruction performed by Processor A is mimicked at the exact same time on Processor B. The content of Memory A is an exact mirror of the Memory B's content. Each I/O received by Controller A is duplicated by Controller B. Mirror set B receives the exact same data as Mirror set A. The duplication is complete except in the operation of the network. The network interface cards, while redundant, have one and only one network link at one time in compliance with network rules. Should the network card interface fail, the redundant network card would become enabled.
There was a system bearing a resemblance to the diagram in Figure 3.5 called the FT3000, manufactured by Digital Equipment Corporation. This system even had a way to signal an AC power loss. The system had an electromagnet, which was energized with the system power. When energized, the electromagnet suspended a metal plate such that only half of the plate was visible-the half with green paint. When system power was switched off or lost, the electromagnet lost power and the other half of the metal plate slid into view-the half with red paint.
An unstoppable setup? Not exactly. The Achilles' heel of such a server is the operating system itself along with its operating applications. If an application or the operating system executes a fatal system instruction-for example, an improper memory reference-then both processors and both memory areas are affected. This powerful fault-redundant system will crash. This is why fault tolerance itself does not a cluster make. If two such systems, as described, were working in a cluster configuration, that would indeed be a highly available cluster solution. Therefore, Digital Equipment did offer an FT3000 cluster with two FT3000s as the cluster members. To be sure, one had to have a big wallet to consider that solution.
3.6 Replication
Replication, in short, is the reproduction or duplicate writing of data. Microsoft's Windows NT 3.1 had a replication service that allowed an automatic distribution of login scripts and related small-sized (preferably less than 10 Kbytes) accessory files from an Export Server to an Import Server.[1] The Replication service was never meant to be more than a convenience. Still, the idea of automatically distributing data sounds like an excellent method of keeping updated copies of valued files (see Figures 3.6 and 3.7).
Figure 3.6: Replication.
Figure 3.7: Replication-one to many.
Wow! Figure 3.7 shows how to get three perfect copies of the original, or one to many including a backup and distributions to the branch offices. But, wait. What if file.cmd is somehow corrupt, or becomes 0 blocks. With a replication service there is the ever-persistent problem of garbage in-garbage out (GIGO). Whatever is on the export side becomes the import side. The point of this is to show that some forms of replication are not always a means of providing high availability.
Replication has been used as a general term to apply to sophisticated service applications that can substantially increase the user's availability and reliability. Services of this nature can be volume, file, or even a mirrored image.
Volume replication (see Figure 3.8) provides the ability to replicate or copy changes to a volume to a remote location. The term "volume" is the logical reference of one or more partitions. Note that a letter identifies the volume. Note also that the destination partition does not necessarily have the same letter as the source. The connectivity is by traditional network or Fibre Channel.
Figure 3.8: Volume replication.
Still, users must keep in mind that drive replication is not mirroring. Mirroring (see Figure 3.9) requires two equally sized partitions on two physical drives. The partition drive letter on both partitions will be the same. This is not the case with replication.
Figure 3.9: Partition mirroring.
[1]The Replication service discussed here is not part of the Microsoft Windows 2000 product line. Replication can be one to one or one to many and is offered as a layered product service by many vendors.
3.7 Shared disk and shared nothing disk
In Chapter 2, "Crystallizing Your Needs for a Cluster," a choice was presented for the storage subsystem-a shared disksubsystem (see Figure 3.10) or a shared nothing disk subsystem (see Figure 3.11). Briefly reviewing that information, a shared disk is a disk that can accommodate simultaneous access from two or more computer systems. To prevent one system from "stepping" on the data of the other system, each system has a copy of a lock management database to synchronize the access.
Figure 3.10: Shared disk.
Figure 3.11: Shared nothing disk.
The shared disk (see Figure 3.10) has the following characteristics:
§ Minimal application adaptation
§ Fast access by either cluster member in a read-intensive environment
§ More expensive to implement than shared nothing
A shared nothing disk is a disk that accommodates asynchronous access from two or more computer systems. This means that at any given time, one and only one computer system has exclusive access to the disk. Control is granted to an accessing cluster member by switching control. For SCSI-3 connections, the switching is done at the SCSI-3 controller. Switching must be kept at a minimum for optimum performance.
With the advent of SCSI-3, especially Fibre Channel, the speed and ability to switch access control from one computer system to another became noteworthy. Even moderately priced storage subsystems with SCSI-3 controllers are able to change control between cluster members in less than five seconds.
The shared nothing (see Figure 3.11) disk has the following characteristics:
§ Typically requires application adaptation
§ Switching between servers impedes performance and should be minimal
§ Less expensive to implement than shared disk
3.8 SAN versus NAS
The storage subsystem of a cluster solution provider may offer two basic alternatives to local system storage. These two alternatives have entered the marvelous world of buzzwords.They are called the storage area network (SAN) and the network attached storage (NAS). Both of these storage systems have been around for quite a while.
A storage area network is a dedicated network for moving data between heterogeneous servers and storage resources. Figure 3.12 shows an example of a storage area network according to the definition, but an "early" edition. Figure 3.13 shows a more modern version of storage area network.
Figure 3.12: Early storage area network.
Figure 3.13: Storage area network.
Some readers may recognize that in Figure 3.12, HSC stands for hierarchical storage controller. These controllers were computers in themselves, specialized to serve disk and tape devices. These separate "intelligent" blocks between computer system and storage took the "serving" load off the computers. The interconnection was much like the interconnection for cable TV.
Cable TV companies harp about thieves "stealing" cable because it hurts legal customers. The distribution of cable TV is accomplished by a strong multiplexed signal transferred to a transformer, much like a spring flowing into a pool. The clients withdraw the signal from the transformer like wells tapping into the pool. Actually the process is called induction coupling. The point is that energy is pushed into the transformer and taken out. If too many clients-especially "unknown clients" or cable thieves-tap into the transformer, then the paying customers will notice their picture quality decrease.
The transformer in this case is the ring called a star coupler. This is actually a torroidal transformer that the computers and hierarchical storage controllers connect to like clients to cable TV. As with cable TV, the number of clients is limited. Storage area networks commonly use SCSI or Fibre Channel at speeds greater than 160 MB/second for the interstorage communication.
Network attached storage(NAS) (see Figure 3.14) consists of an integrated storage system (e.g., a disk array or tape device) that functions as a server in a client/server relationship via a messaging network. Like storage area networks, network attached storage is not "new." This type of storage includes two variations-indirect and direct network served devices.
Figure 3.14: Network attached storage.
Indirect storage should look familiar to some readers as it follows the form of a dedicated computer server offering a directory, partition, disk, or disks as a network share. This model of indirect network attached storage is not meant as a bias toward Microsoft. Sun Microsystems, Inc. was the patent developer of network file system (NFS). Network shares and the "universal naming convention" as used by Microsoft operating systems can be traced to IBM and a product called LanManager.
Direct storage does not require an intermediary computer server. One of the first implementations of this type of storage was the local area disk introduced by Digital Equipment Corporation. A major limitation of that implementation was its restriction to the proprietary local area terminal protocol.
Network attached storage is a variation on network attached printing. Hewlett Packard introduced an impressive method of circumventing the need for a computer as a print server using data link control protocol.

Comments